
My Thesis, Narrated
I recently defended my Ph.D. thesis. While I was preparing it, my advisor mentioned that nobody reads the thesis nowadays in the field of deep learning. Instead, people read individual chapters, which are often published earlier as conference or journal articles. They are also easier to digest. This prompted me to take an extra step: I decided to write a blog post version of my thesis, supported with the slides, to reach a broader audience. You can think of this post as a polished transcript of the presentation I gave to my thesis committee.
This post assumes you know the basics of deep learning. If you are not familiar to the field, you might find this short video and this wonderful playlist helpful.
Problem
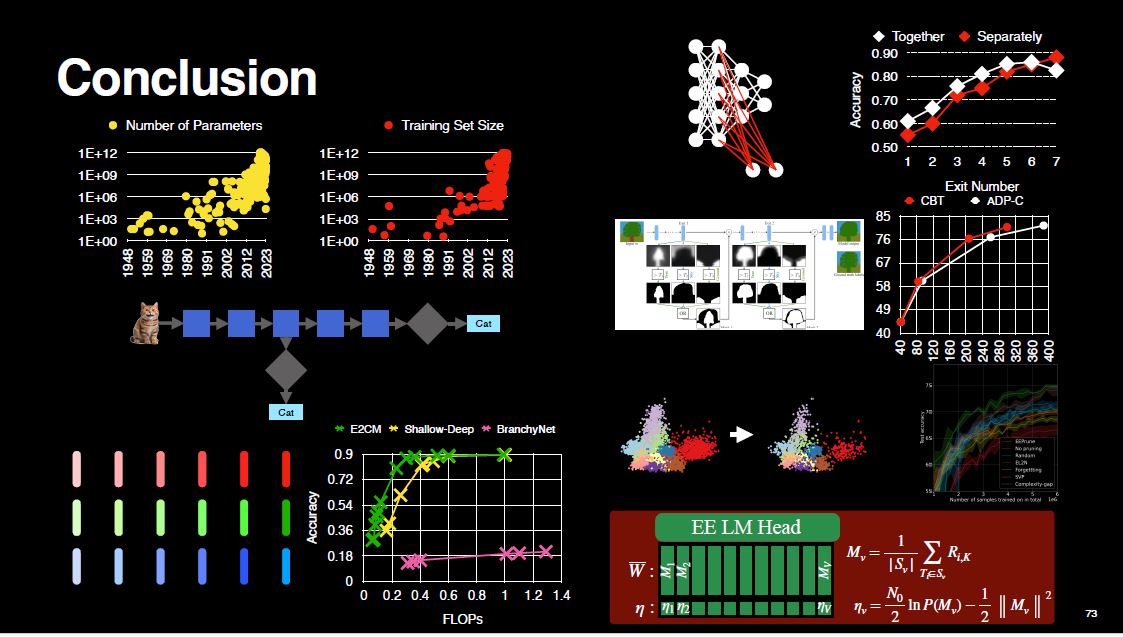
Let’s look at two figures. On the left, we see how number of parameters in neural networks evolved over time. Models got larger and larger because more parameters generally meant better performance on a given task. However, more parameters also mean that models perform more calculations, consuming more energy during inference.
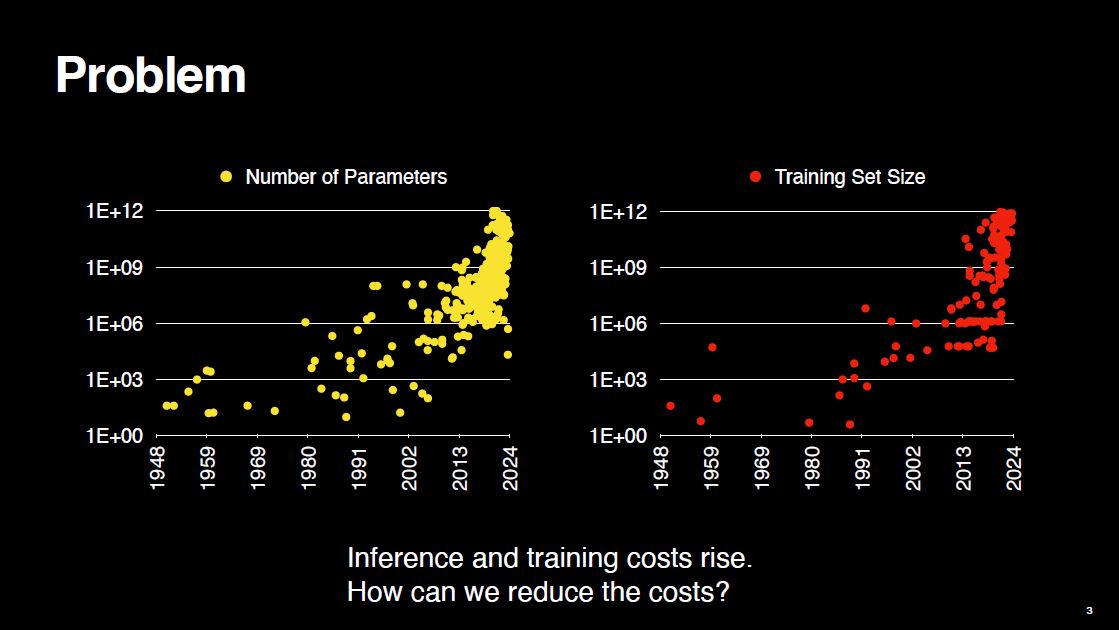
On the right, we see the same exponentially increasing trend for the training set sizes. Larger models are trained on larger datasets for the same reason of better performance, but this leads to a rise in training costs.
The increase in inference and training costs is a significant problem, especially for resource constrained settings such as mobile phones and IoT devices. The increasing trend does not seem sustainable. So, in my Ph.D. research, I explored this question: How can we reduce these costs?
Early Exit Networks
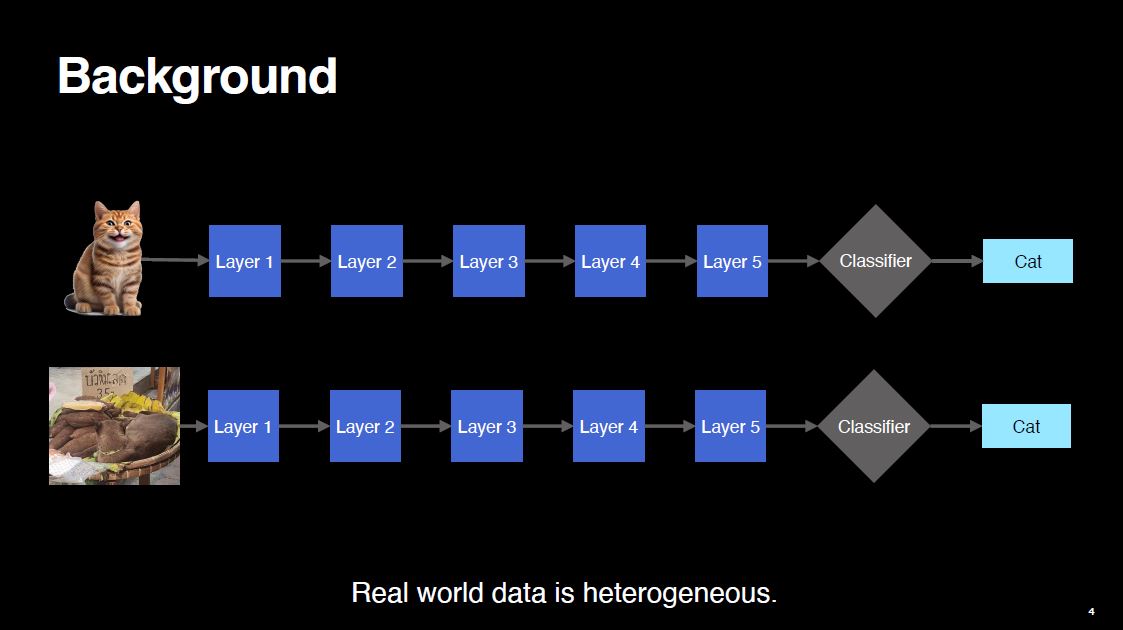
Suppose we are doing image classification. The input image flows through the network. In the end, the network predicts a class.
Traditional neural networks are tunnel-like. In other words, there is one entry point and one exit point. This design forces the network to spend the same amount of compute on every input, regardless of the input difficulty.
However, we know the data in real world is heterogeneous. There are some easy-to-classify samples and some difficult-to-classify samples. For instance, consider the two cases below. It seems sub-optimal that the network performs the same amount of computation for both images (both are cat).
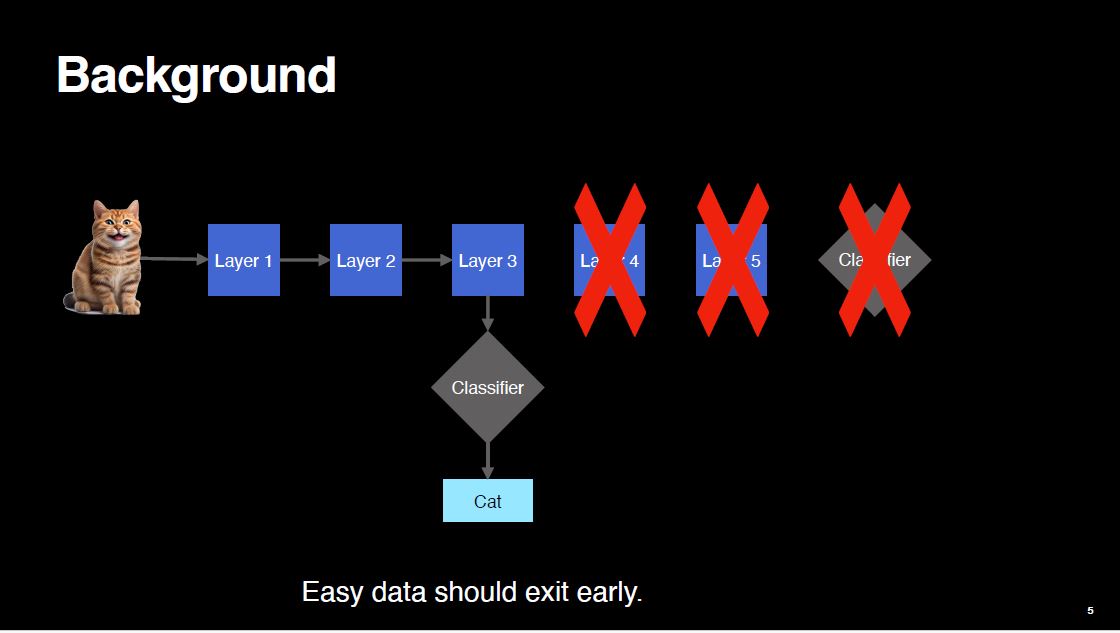
Ideally, we want easy samples to be processed less. The computation should be terminated earlier. The sample should exit early from the network. By doing so, we will save some amount of compute because the subsequent layers will not be executed.
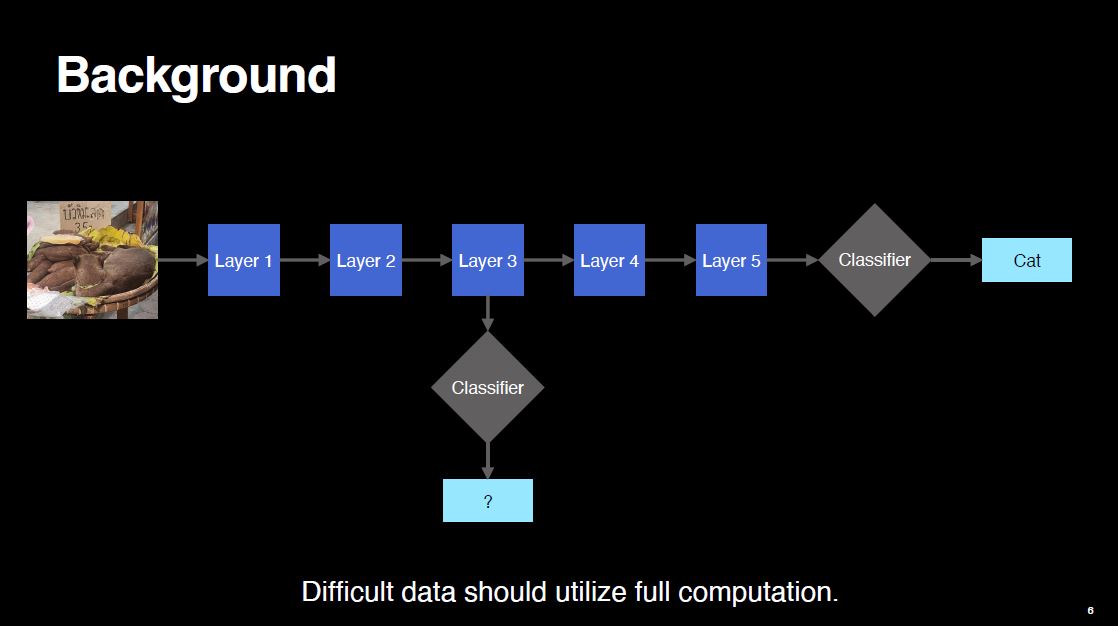
On the other hand, when the input is difficult, it is likely that the input will be classified confidently at the early exit. Therefore, the sample should continue its flow through the network, and it should utilize the full amount of computation.
These are the underlying ideas behind early exit networks. My research uses early exit networks to reduce inference & training costs. Now, let’s explore my thesis contributions in detail.
E$^2$CM: Early Exit via Class Means for Efficient Supervised and Unsupervised Learning
Early exit networks reduce the amount of computation by allowing easy samples to exit early. But to do this, an early exit layer has to be attached to an off-the-shelf, already trained backbone network. This modifies the overall network architecture, which might not be desirable. Secondly, the early exit layer has to be trained to perform well. It will be useful only then. Also, the attachment of the early exit layer implies the necessity of hyper-parameter tuning. We should answer questions like how big the early exit layer should be, where it should be placed, and how many there should be.

Ideally, we want to perform early exiting without modifying the backbone architecture, without further training, and without hyper-parameter tuning. Now, let’s look at an example that will lead us to E$^2$CM, a simple and lightweight early exit algorithm that achieves our purposes.
Suppose we are doing image classification with 3 classes: cat, dog and bird. Our model is already well-trained and it outputs a probability vector of size 3. Let’s say the first, second and the third elements correspond to cat, dog and bird classes respectively.
When we input a cat image, the model’s output vector will have its first value as the largest, because the model correctly identifies it as a cat. Similarly, for a dog image, the second value will be the largest, and for a bird image, the third value will be the largest. To make this easier to visualize, let’s use color-coding. We’ll assign red to “cat,” green to “dog,” and blue to “bird.” The more a vector is tinted red, the more likely the model thinks it’s a cat. The same logic applies for the other classes.
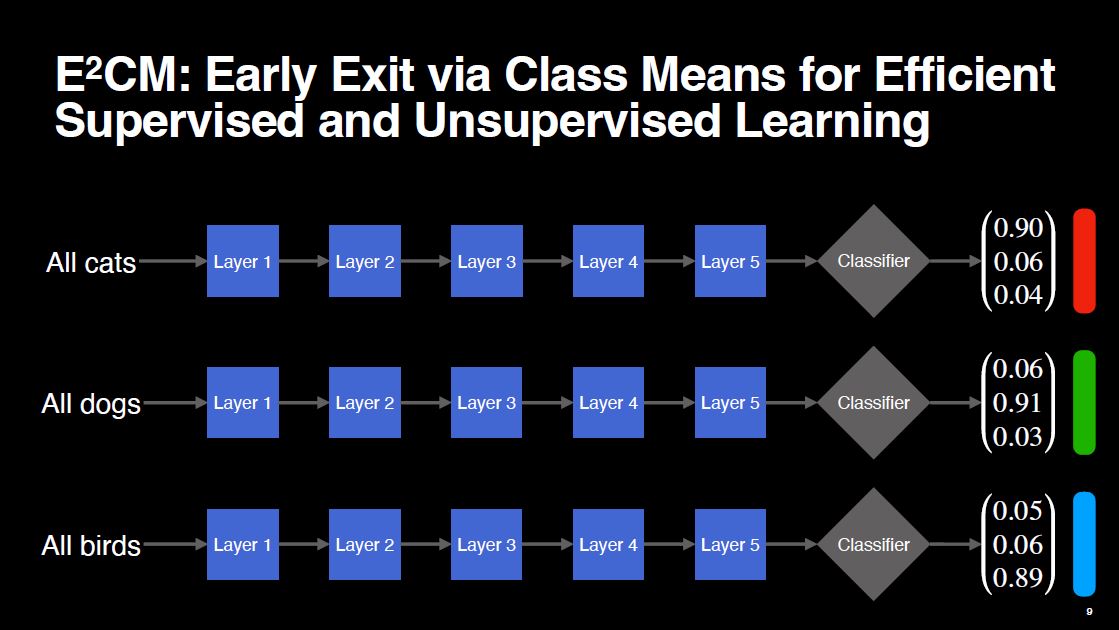
Now, suppose we input every training image that belongs to a particular class, and calculate the average of model outputs. This average vector will again look red, green and blue respectively for our 3 classes, because the model has seen these training images and can confidently classify them.
Here is where it gets interesting: When we average the layer outputs for each class at earlier layers, we still see faint shades of red, blue and green (note that the layer outputs here have larger sizes, i.e. they do not have 3 elements, but much more). This suggests that earlier layers can still extract some useful features which can be used to classify the input at that point of the network. If so, why do not we use these class mean vectors for early exiting?

We propose doing the following. At inference time, the input passes through layer-1. We calculate the Euclidean distance between the layer-1 output, and the corresponding class mean vectors. We convert the distances to probabilities by taking the softmax over negative distances. This ensures that a larger distance means a lower likelihood of belonging to that class. Finally, we check if the maximum element of the softmax vector is greater than a pre-defined threshold. If so, it means layer-1 output for the test image is close enough to a class mean, it probably belongs to the corresponding class, and it can exit early. Otherwise, the computation should continue. This is the E$^2$CM algorithm.
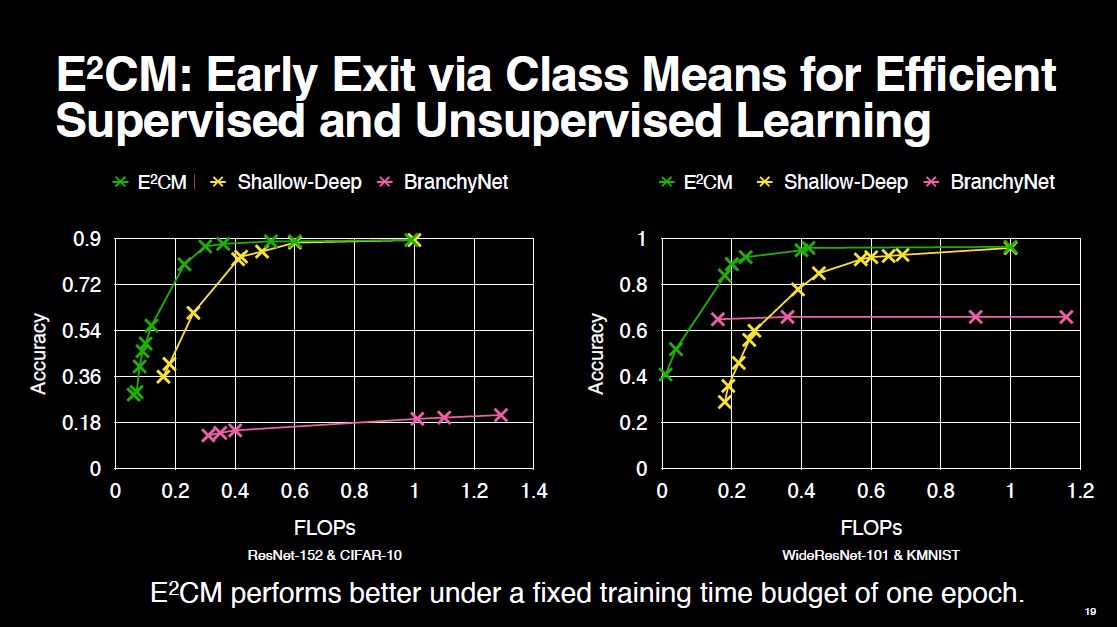
We compare E$^2$CM against some other early exiting methods under a fixed training time budget of one epoch, as E$^2$CM requires only one forward pass and it does not require gradient based training. This makes E$^2$CM particularly suitable to resource constrained settings. As we see from the figures, E$^2$CM outperforms the others.
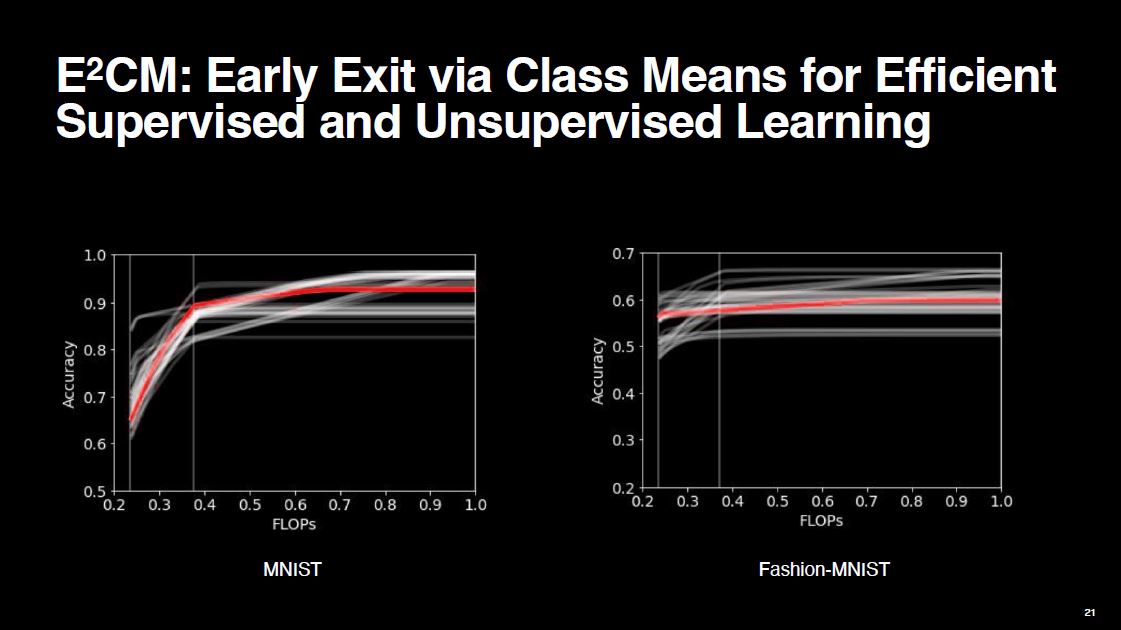
Another good thing about E$^2$CM is that it can be applied to unsupervised learning tasks too. Suppose we are doing deep embedding clustering, which means we are clustering not the raw data, but the embeddings produced by the neural network. At inference time, the embedding of a sample is compared against the cluster centroids at the end of the network. But if the embedding is close enough to an earlier cluster centroid, do we need to execute the subsequent layers? E$^2$CM says no! It can reduce the computational cost by up to 60% with negligible performance drop.
To sum up, E$^2$CM is a simple, lightweight early exit algorithm that reduces the inference cost for low resource settings. It does not modify the backbone model, it does not need any training, and there is no hyper-parameter tuning required.
Pruning Early Exit Networks
In a separate line of research, we explored how early exit networks can be combined with other efficiency optimization techniques, such as model pruning.
In model pruning, the redundant weights are removed from the network by setting them to zero. This results in sparser weights, smaller model size and therefore faster inference. Redundant weights in this context means the weights with the smallest magnitude. After pruning, we typically fine-tune the model to allow the remaining weights to adjust and maintain accuracy. This process of pruning and fine-tuning is repeated iteratively to achieve the desired sparsity and accuracy levels.
In the case of early exit networks, now the model contains the weights of the attached early exit layer. In this work, we wanted to answer the question of how to prune the early exit weights.
We compared two approaches:
- Simultaneous Pruning: In this approach, we prune the backbone weights and the early exit weights together. Then, we fine-tune them together, and repeat the process. Here, all weights are treated the same.
- Sequential Pruning: In this approach, we first prune and fine-tune the backbone weights. When this process is complete, we prune and fine-tune the early exit weights. Backbone weights are kept frozen during the processing of early exit weights.
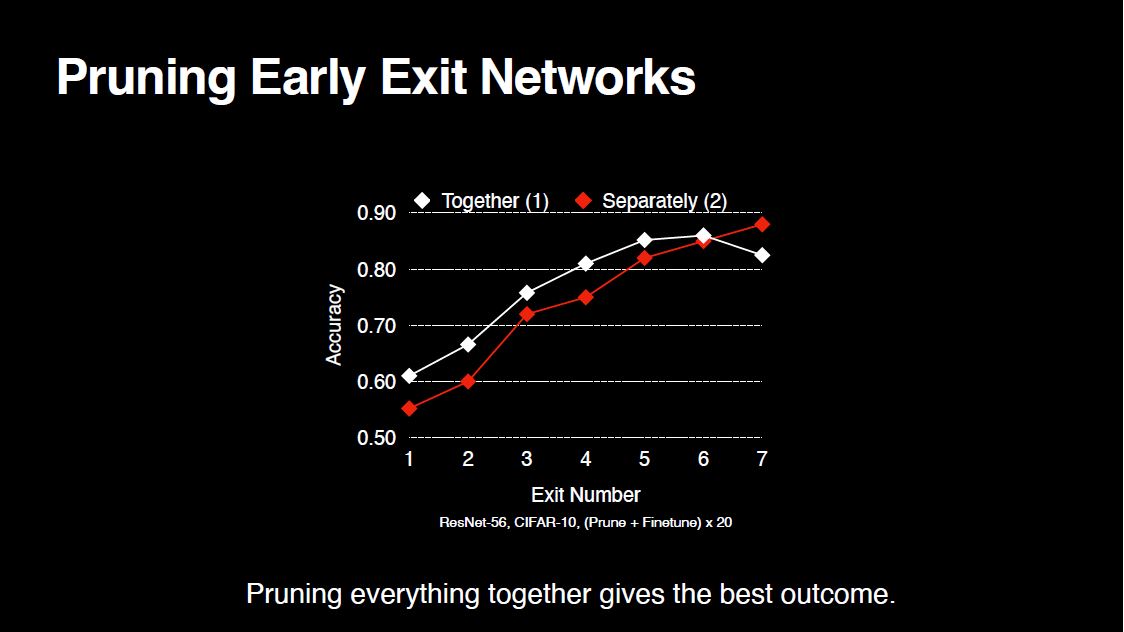
Now, let’s look at the sparsity rates across the layers of an early exit network. We have 7 exits in total, where each exit is a single linear layer.
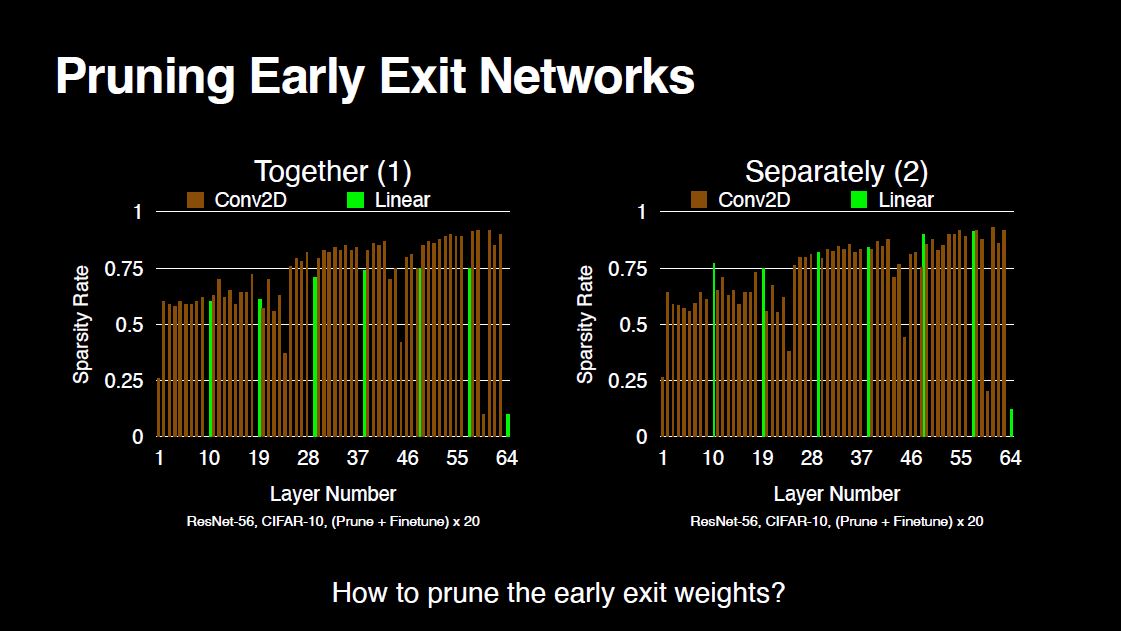
For clearer comparison, let’s look at Approach-1 minus Approach-2.
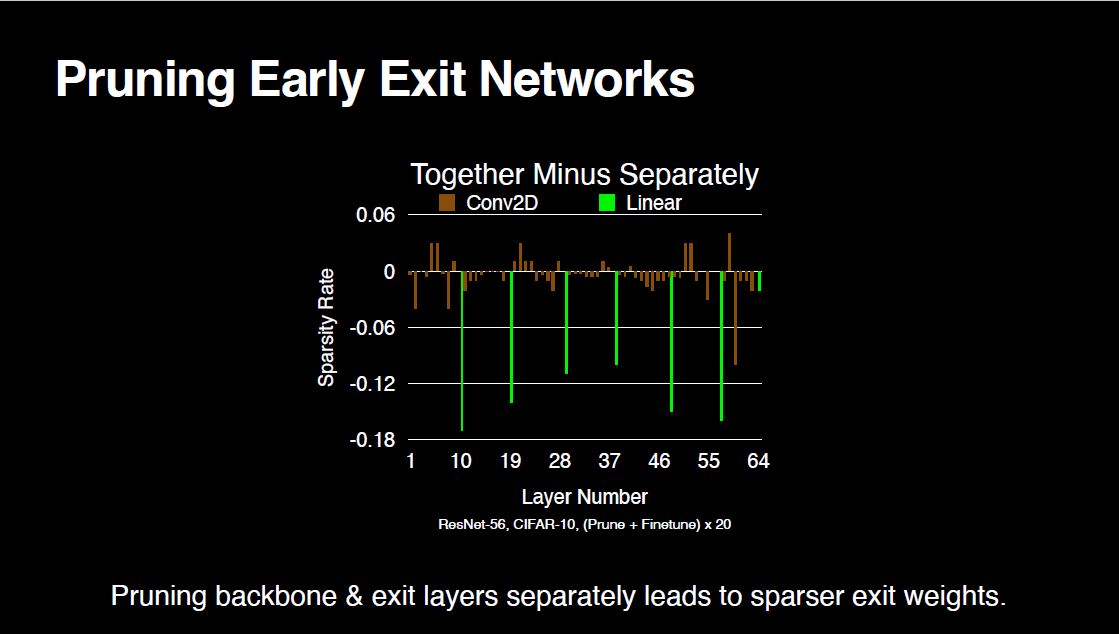
As we see, Approach-2 prunes the linear layer weights more, which leads to sparser exit weights. As a result, exit performances are worse for Approach-2. So, the key takeaway from this work is that for the best overall exit performance, it is best to treat all weights the same.
Class Based Thresholding in Early Exit Semantic Segmentation Networks
We designed a new algorithm called CBT, which further reduces the inference cost of early exit semantic segmentation networks. In semantic segmentation, the goal is to classify each pixel in an input image into a set of classes.
In order to reduce the inference cost, researchers have added an early exit layers to the backbone network and trained them. At inference time, subsequent computations stop for the pixels that are predicted confidently at the early exit point. Here, confident means the maximum prediction probability for the pixel exceeds a pre-defined threshold. Previous works in the literature have used the same threshold value for all classes.
We make the following observation: Not all classes have the same classification difficulty, therefore using the same threshold value for all classes is sub-optimal. For example, compare the road and human classes shown below. Inherently, they have different difficulties of being predicted correctly because of their perceived size, location and neighborhood pixels. Also recall the heterogeneous real world data hypothesis from E$^2$CM. It makes sense to use different threshold values for different classes. This is what CBT does.

Here is how CBT works:
- Suppose we have $N$ exits and $K$ classes.
- Let $\phi_n$ be the probability vector for a pixel at exit $n$. This has $K$ elements that sum up to one.
- Let $S_k$ be the set of of all training pixels with ground truth $k$.
- For every class $k$, at every exit $n$, we calculate the average $\phi_n$ for the pixels in $S_k$. This is $p_{n,k}$.
- Then for each class, we calculate the average of $p_{n,k}$ across all exits. This is $P_k$. You can think of this step as information sharing between the exits.
- We then initialize the threshold for class $k$ as the difference between the largest and second largest elements of $P_k$. This is a confidence level. The higher it is, the more confident the model is. However, we want high confidence to be matched with low thresholds, so we inversely map $T_k$ to a range between $[\alpha, \beta]$. $\alpha$ is the lowest threshold that is assigned to the easiest class, and $\beta$ is the highest threshold that is assigned to the most difficult class.
The overview of CBT is shown below. Notice how the exit outputs are split into channels, each channel is compared to its own threshold, and the resulting masks are merged before being incorporated to the backbone computation flow. By assigning different threshold values to different classes, CBT allows computation to stop even earlier for easy pixels. This further reduces the inference cost.

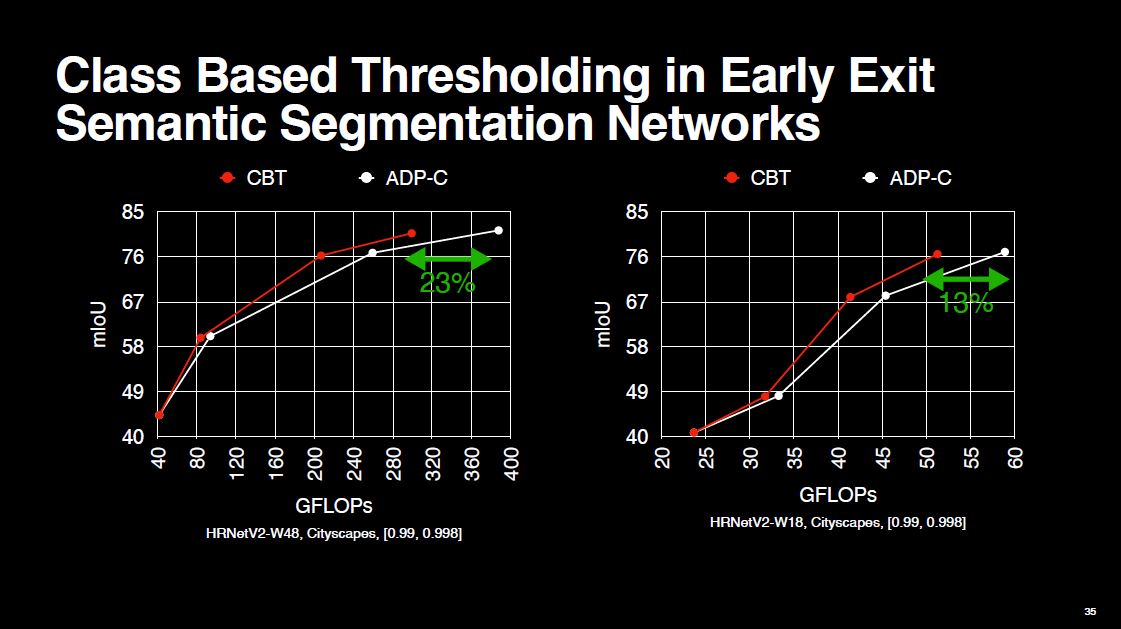
Now, let’s look at the results. We compared CBT against ADP-C, which uses the same threshold value of 0.998 for all classes in the Cityscapes dataset. For CBT, the thresholds are between 0.9 and 0.998. As shown, CBT can reduce the amount of compute by up to 23%.
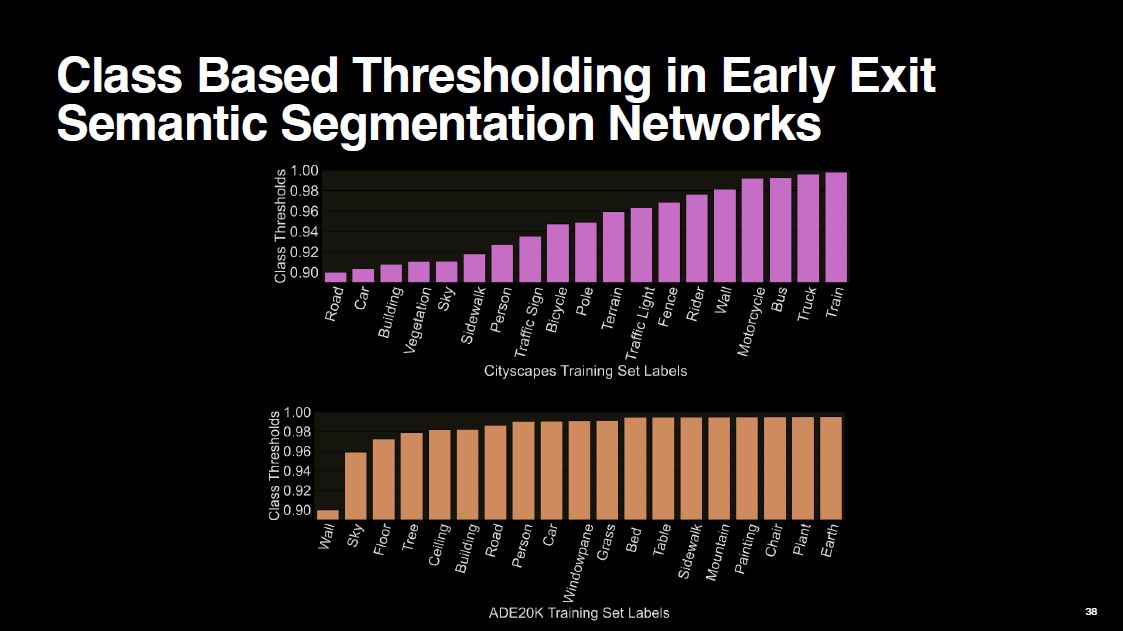
Finally, I would like to show you which classes received lower thresholds and which ones received higher thresholds. For Cityscapes, the road class has the lowest threshold, which means it is the easiest class among all. On the other hand, the train class has the highest threshold. The exact order might not be 100% correct, but the general trend is logical: Simpler classes such as road and sky have lower thresholds. On the more challenging ADE20K dataset, most classes have high thresholds, which makes sense given the dataset’s greater complexity compared to Cityscapes.
Dataset Pruning Using Early Exit Networks
Up to this point, I have discussed my works on reducing inference costs. Now, let’s shift our focus to reducing training costs. I will introduce a novel dataset pruning algorithm called EEPrune.
Dataset pruning aims to reduce the training set size by identifying redundant, uninformative samples. The goal is to ensure that when the model is trained on the remaining samples from scratch, its learning and generalization ability stays intact, and the test set performance is not compromised.
There are a couple of problems with the existing dataset pruning algorithms though. First of all, they are costly. For example, some methods use an ensemble of models to identify the redundant samples, while others perform a full training run to do so. Such approaches result in the costs outweighing the benefits. Moreover, many of these sophisticated dataset pruning techniques cannot beat simple random pruning.
As I stated above, in some sense, early exit networks can detect easy samples. We developed EEPrune based on this insight. Specifically, after a brief training period (just a few epochs) EEPrune discards a sample if three conditions are satisfied:
- The sample is correctly classified by the early exit,
- The sample is correctly classified by the final exit (this is important because we want to avoid overthinking, where the prediction might change between the two exits),
- The early exit is confident about its prediction.
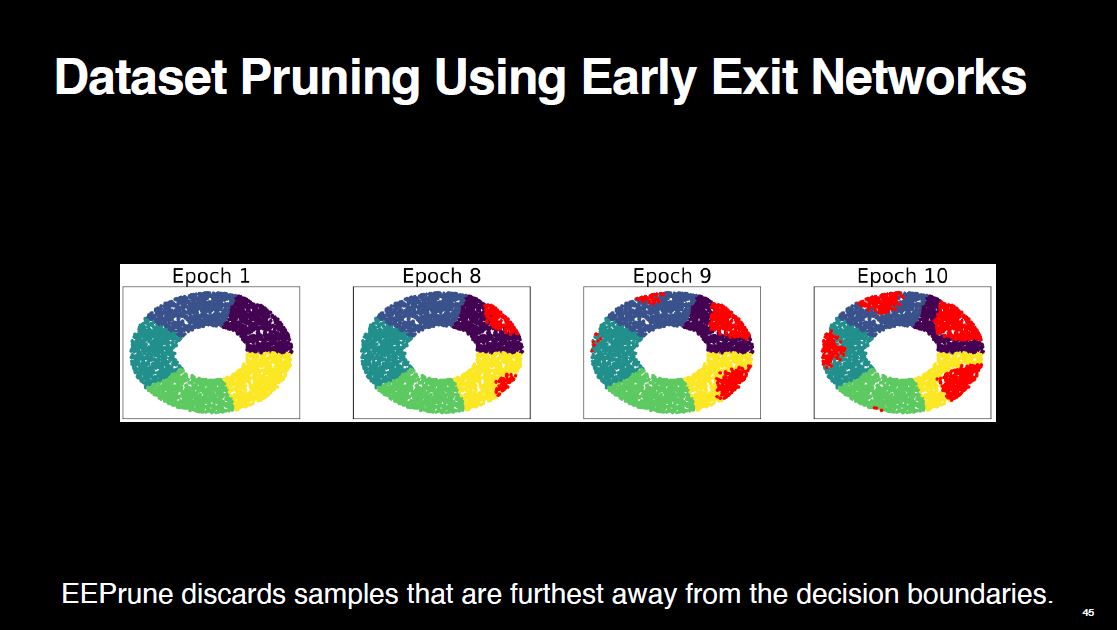
When we look at which samples are pruned on a toy, easy-to-visualize dataset, we see that EEPrune discards the samples that are furthest away from the decision boundaries. This indicates that those samples are less important for the training, which makes sense.
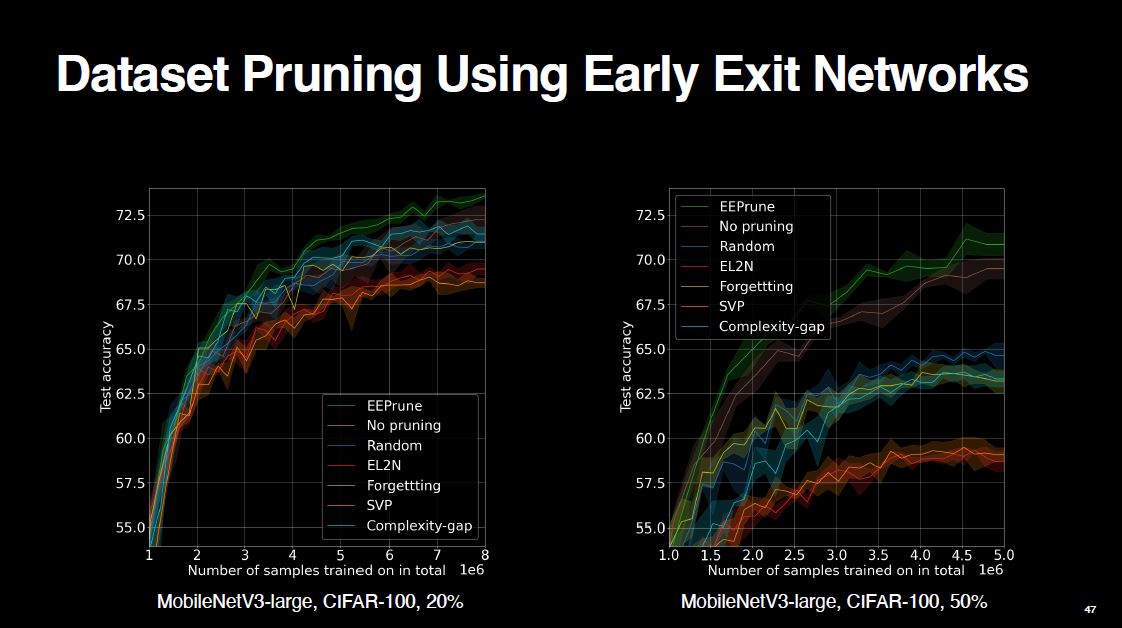
Now, let’s see the results. As demonstrated, EEPrune beats random pruning as well as other more sophisticated pruning methods. For more detailed figures and insights, you might want to take a look at the thesis.
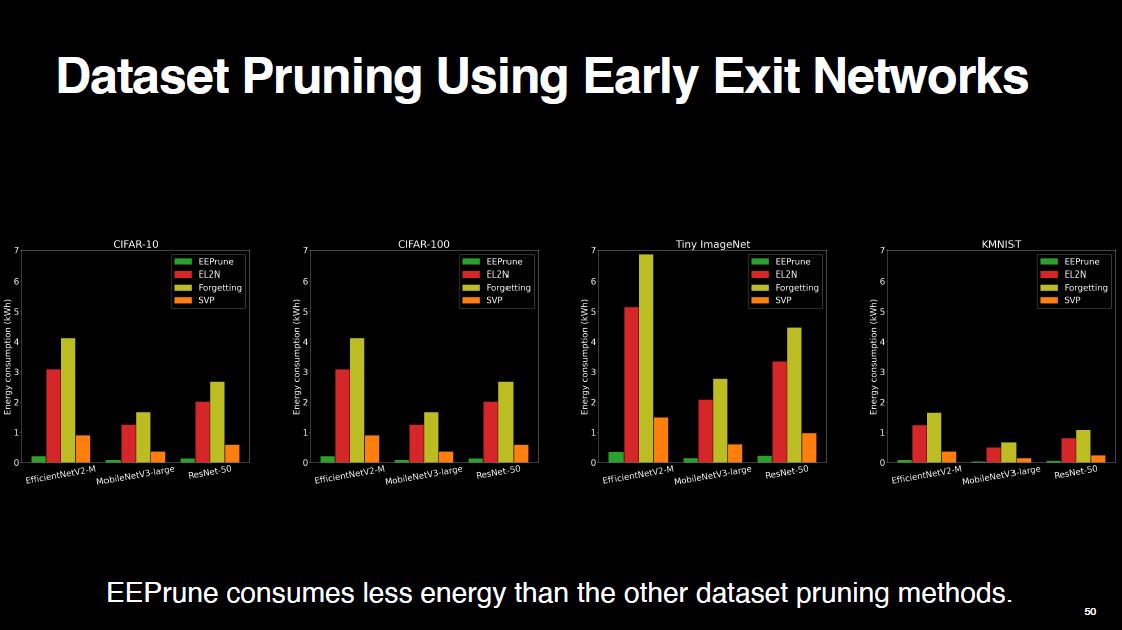
EEPrune also consumes less power compared to the other methods because it requires only a few epochs of training. This does not contradict the main objective of reducing the training costs, unlike other methods.
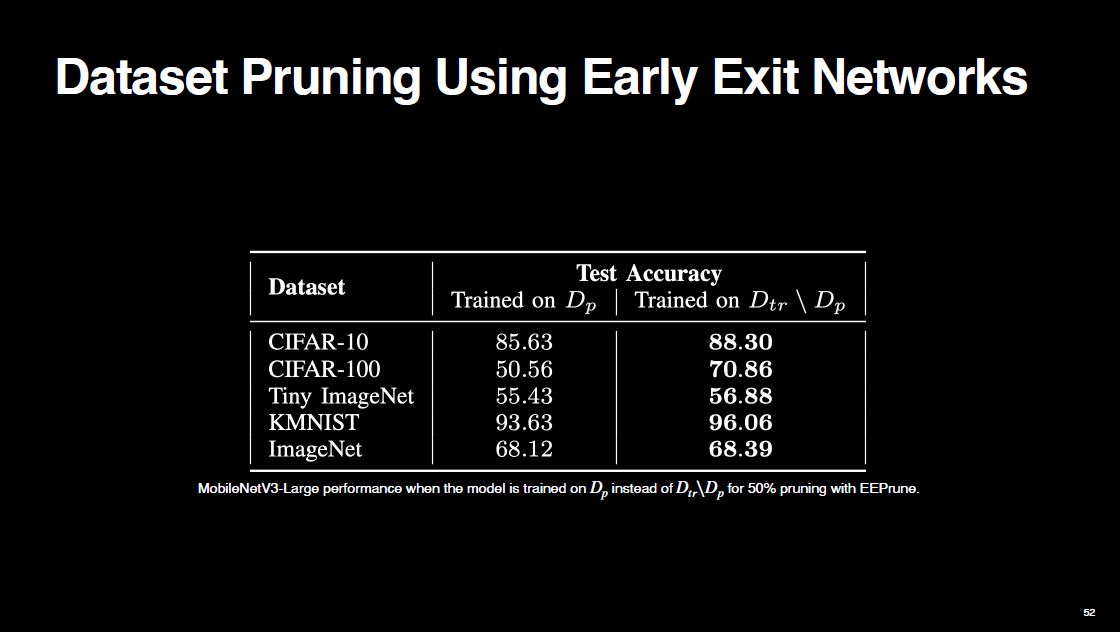
We validate the effectiveness of EEPrune as follows. Suppose we are doing 50% pruning. We have identified which samples are redundant. They are in $D_p$. Normally, we train the model on $D_{tr} \setminus D_p$, right? And it performs well on the test set. What if we train it on $D_p$? $D_p$ have the redundant, uninformative samples, so the test set performance should be lower. And indeed this is the case.
We also examine the effect of the exit location. Across all pruning ratios, our findings indicate that placing the exit too early or too deep in the network hurt the performance. So, as everything else in life, there must be a balance.

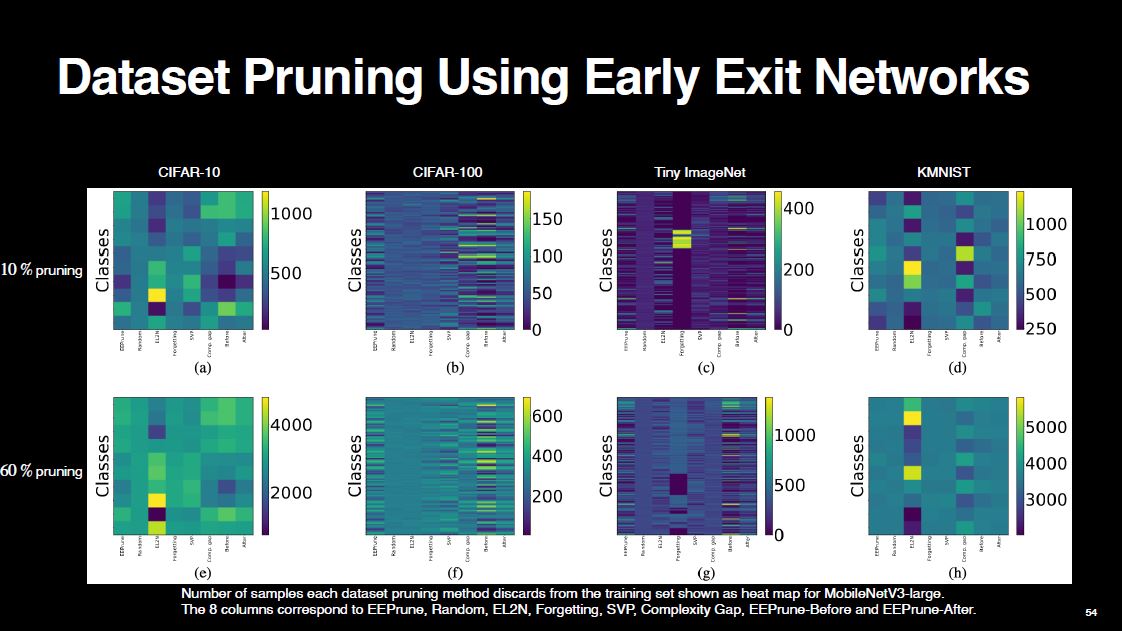
Finally, I want to show you a visually appealing figure that displays heatmaps of different dataset pruning methods. These heatmaps illustrate how many samples each method discards from each class. As you can see, each pruning method behaves differently and causes a different level of class imbalance in the remaining set. Random pruning, the second column from the left in each heatmap, appears the most uniform, as expected. On the other hand, some methods cause a significant class imbalance, which explains their poor performance.
Class-aware Initialization of Early Exits for Pre-training Large Language Models
My final contribution is a weight initialization technique for accelerating the pre-training of early exit large language models (LLMs).
LLMs today are too big, so inference times are too high. As I explained before, we can reduce the inference time by adding an early exit layer. But we have to train it first. It will be helpful only then. Our goal in this work is to find a smart way of initializing the early exit layer in an LLM. By doing so, we will not have to perform much pre-training for the early exit layer.
For context, let’s study how training is performed for an LLM now. Specifically, let’s focus on the pre-training of a decoder-only LLM.
First, we have some text dataset. We cannot feed it directly to the model because we need to convert the text into numbers. The tokenizer takes care of this. Now we have the tokens $T_i$. Each $T_i$ is a number between $1$ and $V$, the total number of distinct tokens in our dataset. Each token flows through the network in parallel, that’s why training LLMs is more efficient than training RNNs or LSTMs.
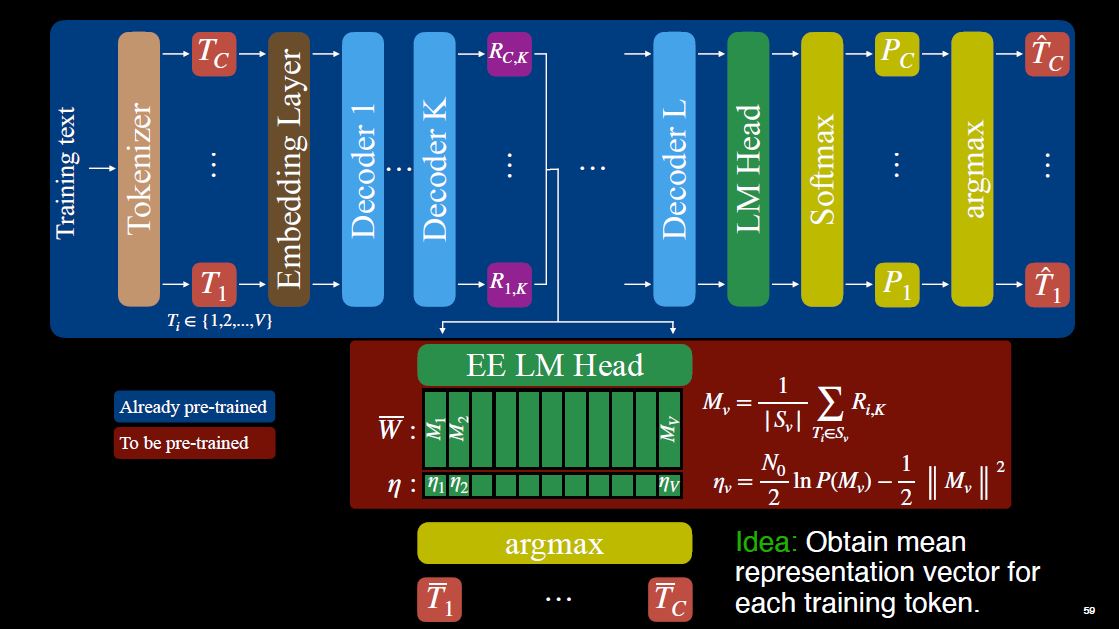
The tokens are then converted to embedding vectors. After that, the vectors flow through the other layers of the model: Decoder-1, Decoder-2, and so on. At the end, the language modeling head, which is a linear layer, converts the outputs of the last decoder layer to token predictions via softmax. The objective here is next token prediction: We want $\hat T_i = T_{i+1}$.
Now, let me explain our weight initialization technique. The backbone layers are already pre-trained. Let’s say we add the early exit after Decoder-K. Let $R_{i,K}$ denote the intermediate representations for the tokens after Decoder-K.
We feed the entire dataset to the model, and for each token $v$ in the dataset, we calculate the average of $R_{i,K}$. This gives us $M_v$, the column of the weight matrix that corresponds to token $v$. Using $M_v$, we calculate another term, $\eta_v$, which is the corresponding bias element.
At inference time, the early exit layer simply performs matrix multiplication between $R_{i,K}$ and its weights. Since the dot product of similar elements yields a larger value, our approach draws parallels to E²CM by examining the proximity of tokens to their mean representations.
Our weight initialization technique has ties to the telecommunications domain, specifically, to the problem of optimal detection for the vector AWGN channel.
The vector AWGN channel can be modeled as $r = s_m + n$. Each term is an $N$-dimensional vector. There is a sender, which can send $M$ different messages to the receiver through the AWGN channel. The channel adds the noise. The noise components are IID Gaussian with zero mean and $\frac{N_0}{2}$ variance. The goal for the receiver is to minimize the probability of error.
Using Bayes rule and clever mathematical tricks, when we expand the problem formulation step by step, we end up with the expression shown below. Notice how it resembles the operation of a linear layer: A matrix multiplication of weights and the input, plus the bias.

Now, let me discuss the experiments. We have two settings. In the first one, referred to as the no-freezing setting, all layers of the model are trainable. In the second setting, we freeze all layers except the language modeling heads. This configuration simulates a resource constrained scenario.
We compare our weight initialization technique against two baselines. The first baseline is simply initializing the early exit weights in a random manner, using uniform distribution. The next baseline is copying the weights of the final exit into the early exit. We can do this because the final exit is already pre-trained, and the dimensions match.
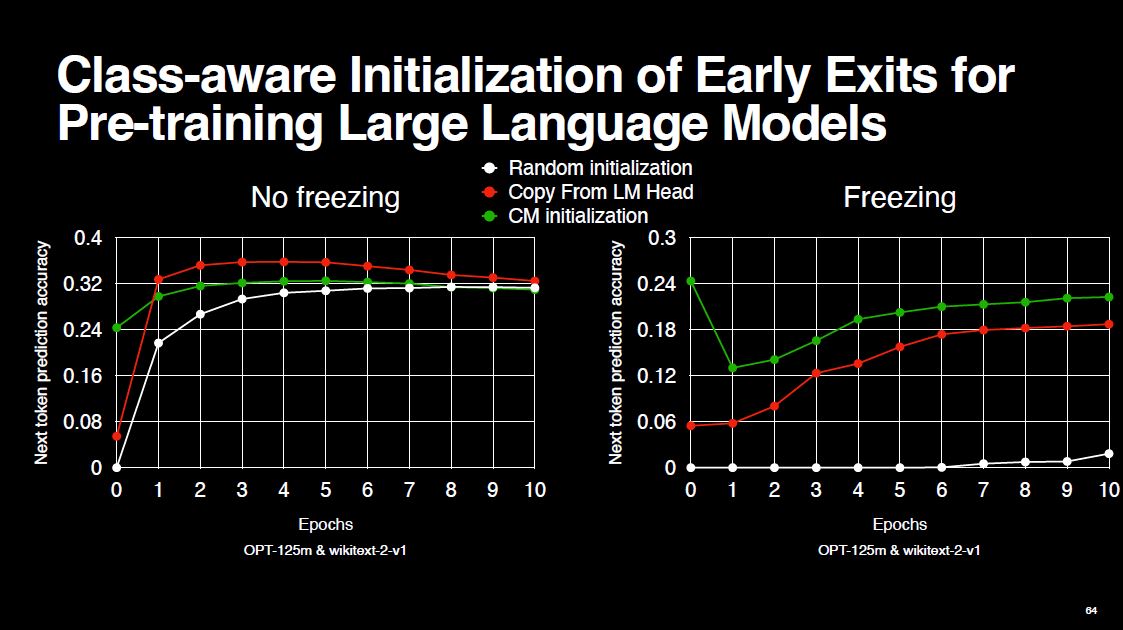
As shown above, with absolutely zero training, our class-aware weight initialization technique can achieve 24% next-token prediction accuracy in the no-freezing setting. This is a pretty good deal! However, after a few epochs, the green curve stays under the red one, which is not ideal. On the right, we see that the our technique is simply the best.
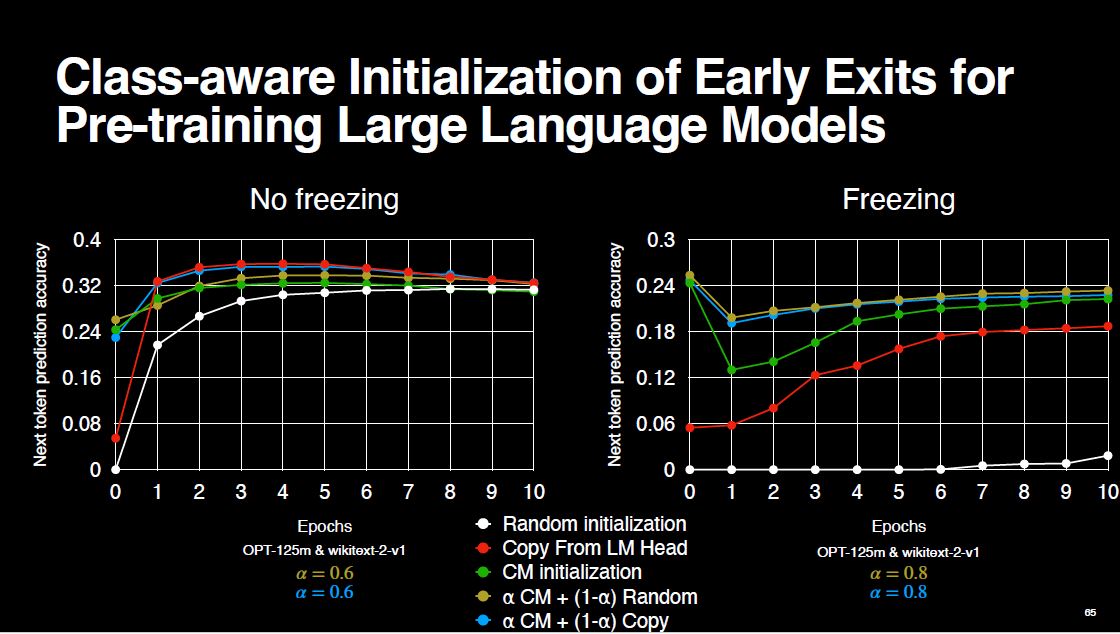
We solve the problem of staying under the red curve by using a convex combination of our class-aware technique and the copy-from-final baseline. By doing so, we start from a very good place, and we keep high performance throughout the pre-training. We keep the best of both worlds. This also boosts the performance in the freezing setting as well. For more figures on bigger models and different model families, you can refer to the thesis.
Future Work
If someone picks up my thesis, here are some problems they might want to start working on first.
E$^2$CM requires a class mean vector for each class. In open world scenarios, we might encounter unknown classes. It is not immediately clear how E$^2$CM should handle these situations. Additionally, there is more room for improvement in terms of computational cost. Pooling and quantization could make E$^2$CM even more efficient.
Combining early exit networks with model pruning seems straightforward. There are other model efficiency techniques such as quantization and knowledge distillation. As far as I know, there is no research that investigates the optimal combination of these four techniques.
CBT uses different thresholds for different classes, but our experiments considered only one modality. In multi-modal settings such as image generation, one might want to use different thresholds (or ranges of thresholds) for different modalities.
EEPrune could potentially be applied to unsupervised learning tasks such as clustering, but experimental validation is needed. Also, whether it may be used for filtering training data for LLMs is an interesting research question.
Finally, there may be even more clever weight initialization techniques for the supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) phases for LLMs. Only the most adventurous researchers might uncover these techniques!
Concluding Remarks
In the penultimate semester of my Ph.D., I read Umberto Eco’s How to Write a Thesis. Although it is mainly written for social sciences, philosophy and literature, the insights apply broadly no matter your area of study. I already knew most of the things the book covered, but it was still worthwhile and enjoyable read.
According to Eco, writing a thesis provides a unique research experience that will always be useful throughout life. He emphasizes that the journey is more important than the specific topic you choose.
I think I was lucky enough to be exposed to different problems during my Ph.D., both at school and in the industry via internships. I had the chance to tackle interesting problems, organize my thoughts and data, and communicate insights in an easy-to-digest way. The cherry on top has been my research topic. Efficient inference & training is more crucial today than ever. I hope Eco is right and the experience I gained throughout the Ph.D. will prove useful whatever work lies ahead
If you found this post or my thesis useful for your research, please consider citing them.
Published: Nov 7, 2024.
Last edited: Nov 7, 2024.